Tools fail. Your agent shouldn't.
Tools fail constantly, and what separates an agent that recovers from one that stalls or spins isn't a smarter model. It's where you handle the error.
In the last piece I walked through the ReAct loop: reason, act, observe, repeat. The “act” step is almost always a tool call, the agent reaching out of the model and touching something real. An API, a database, a file. The whole loop assumes that step returns something useful. One of the first agents I built, a few years ago now, taught me what happens when it doesn’t.
The agent was halfway through a multi-step task and called a search tool. The tool hit a rate limit, threw a 429, and the run stopped dead. One failed call out of maybe forty, and the agent had nothing to offer but a stack trace. That felt obviously wrong. A person who hits a rate limit waits a second and tries again. They don’t put their tools down and go home.
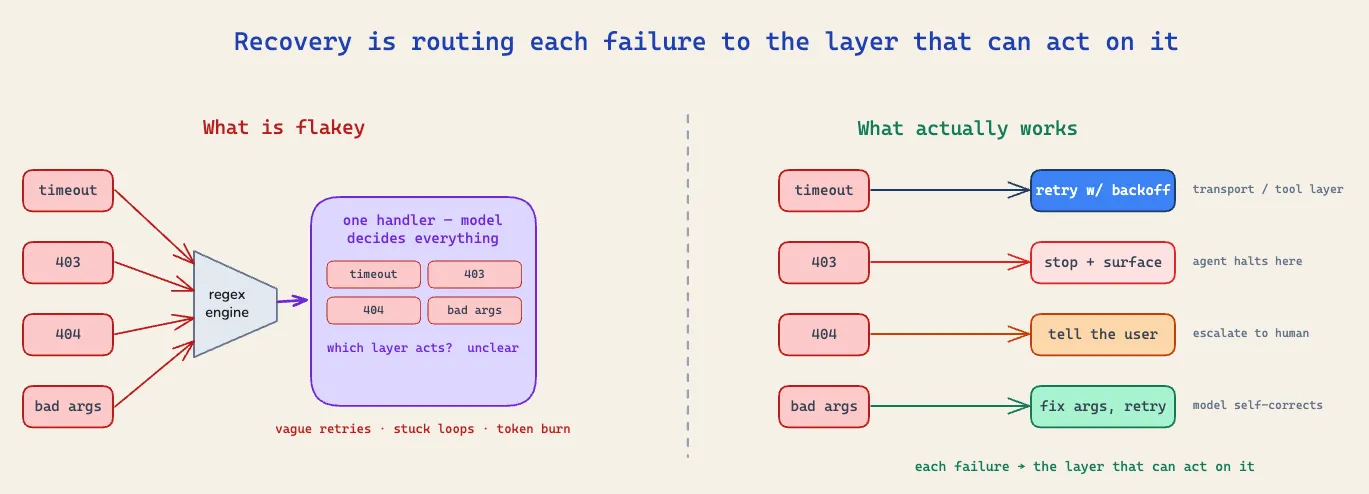
So I did what most people do first. I wrapped every tool in a try/except, caught whatever came back, and turned it into a tidy JSON object I handed straight to the model. It had a category, worked out from a pile of regexes run against the error message. It had a retry_after_seconds. And it had a suggestion field, a polite sentence telling the model what to do next: “Access denied. Do not retry. Surface to the user.” I was pleased with it at the time. It looked responsible.
It mostly wasn’t, and it took me longer than I’d like to admit to see why. The problem was never the wording of the errors. It was that I’d put every decision in the same place and handed all of it to the model, including decisions the model was the worst possible thing to make. A tool-using system that recovers isn’t the one with the best error messages. It’s the one where each kind of failure is handled at the layer that can actually do something about it. Getting that right is mostly a question of asking, for every failure, one thing: is this an error the model can reason about, or not?
Why tools fail, and what “recover” actually means
It took me a while to internalise why tools fail as often as they do, and it comes down to what a tool really is. The model on its own is sealed off from the world: it reads text and it writes text, and that’s the whole of what it can do. A tool is the only way it touches anything real, and early on I half-thought of one as just another function call. It isn’t. A function runs inside your program, where things are predictable; a tool reaches outside it, to fetch a page, run a query, read a file, call another service. Everything a tool does happens outside the model, in systems the model doesn’t control. That’s exactly why they fail. The model is a fairly predictable text generator. The world on the other end is a flaky network, a database under load, an API that decides you’ve asked too often, a file someone moved last week.
I went in treating failures as edge cases to clean up later. They aren’t the edge, they’re the normal condition of doing real work. The network times out, the service rate-limits you, a credential expires, the thing you asked for isn’t there, or you simply send a malformed request. In a forty-step task the question was never whether a tool would fail. It was how many would, and whether the run survived it.
Here’s the reframe that made the rest of it click for me. In the ReAct loop, a tool result is just an observation, the thing the model looks at before it decides what to do next. An error is not a special case. It is just a particular kind of observation. If you let the exception throw, the loop dies. If you catch it and hand it back as a result, the model can treat it as data and reason about it: try again, reach for a different tool, or stop and tell the user. It’s the standard advice now: Anthropic’s tool-use docs tell you to catch the exception and return it as a result, and the MCP spec is blunt about why errors belong in the result rather than thrown: otherwise “the LLM would not be able to see that an error occurred and self-correct.”
That gave me a clean definition to build against. Recovery does not mean a tool never fails, because it will. It means the loop stays productive after it does. The agent either makes progress despite the failure, or it stops cleanly and says so, but it never crashes on something survivable and it never sits there repeating the same broken call. Fail, then keep the loop useful. That’s the entire bar.
Not all tool failures are the same
If the bar is “keep the loop useful,” the next question is: useful how? And the answer depends entirely on why the tool failed. A timeout and a typo’d database column are both “errors,” but the right response to each could not be more different. One you wait out. The other no amount of waiting will ever fix. So before you can decide where a failure goes, you have to know what kind of failure it is.
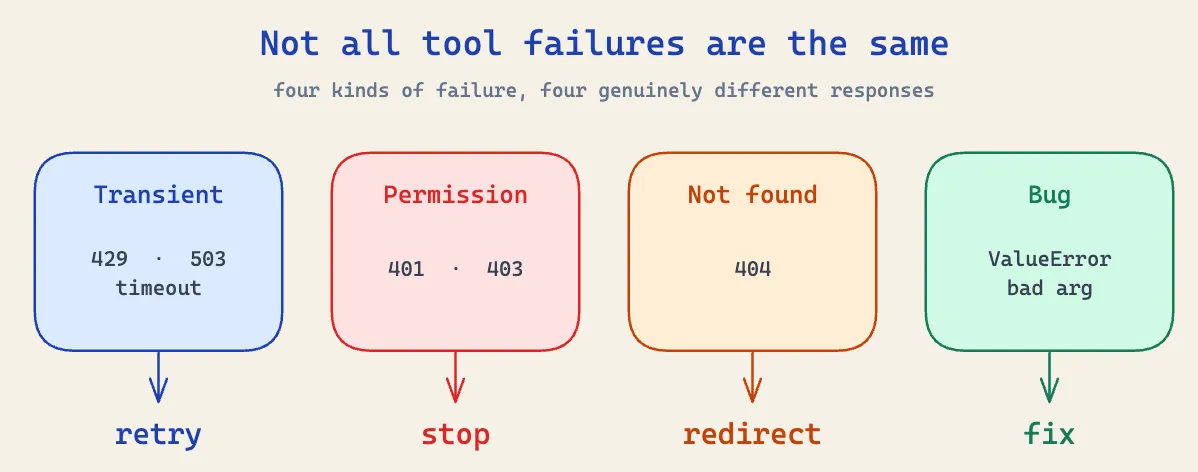
An error-handling system I implement in any agent I build now is to sort every tool failure into four buckets, and let the bucket decide what happens next:
- Transient. A timeout, a 429, a 503, a dropped connection. The world blinked. Nothing is actually wrong with the request, the thing on the other end was just briefly unavailable, and in practice this was the bulk of what I saw. The fix is to wait a moment and try the exact same call again.
- Permission. A 401, a 403, access denied. Here a retry is pointless, because nothing about a second identical attempt changes whether you’re allowed in. The only move left is to stop, usually because a credential needs fixing.
- Not found. A 404, a missing file, no such record. The thing you asked for isn’t there, and asking again gets you the same nothing. The fix is for the model to look somewhere else or pick a different target.
- Bug. A
ValueError, aTypeError, a malformed argument, a required field left blank or a date in the wrong format. The model passed something wrong. The fix is for the model to send a better call, because it’s the one thing in the system that can.
Notice that those four want four genuinely different things: retry, stop, redirect, fix. Lumping them under one word and one handler is exactly the mistake I made back then.
The rule that decides where a failure goes
Once you can name what kind of failure you’re holding, the whole design collapses to a single rule. It’s the thing I wish I’d understood before I wrote the first version, and it’s the load-bearing idea of this whole piece:
Only raise errors to the model that the model can actually reason about. Everything else is the harness’s job.
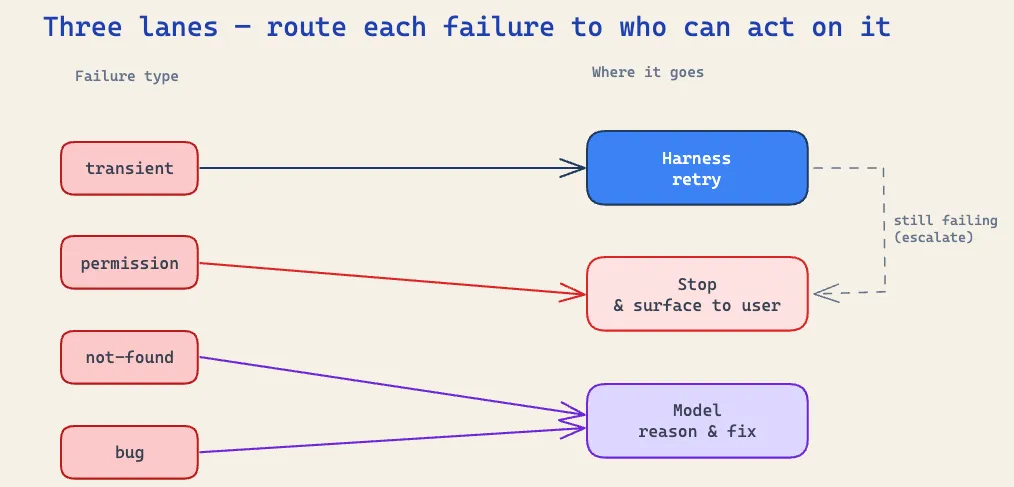
I came to treat the model’s context window as the most expensive real estate I had. Every error I put there cost a full round trip of tokens and a turn of latency, and that’s only worth paying if the model can do something useful with it. Most of the time, with most failures, it can’t. So the four buckets sort into just three outcomes, and only one of them is the model.
- The harness retries. A fresh transient error carries no information the model can act on. There’s no argument to fix, no different tool to reach for, the service was just busy. In that first version I handed 503s straight to the model and watched it spend a whole turn reasoning its way to “I’ll try again,” which is a thing a
forloop does for free. So now the harness retries these itself, quietly, and the model never sees a transient error it doesn’t need to. - The model fixes. Bugs and not-found errors are the ones where the model is the only thing that can help. A malformed argument needs the model to send a better one. A 404 needs it to look somewhere else. These go straight to the model the moment they happen, because its reasoning is exactly the thing that moves them.
- The run ends. Some failures can’t be fixed by anyone. Permission is the obvious one: the model can’t grant itself access and no retry will conjure a credential. The other is a transient that has used up its retries: once the harness has tried and the service is still down, that’s terminal for this run too. Neither goes to the model to “fix,” because there’s nothing to fix. The run stops and the user is told what happened.
That last grouping is the one I missed for the longest. A dead service and a denied credential feel like very different errors, but to the agent they’re the same shape: nothing left to try, so stop cleanly rather than spin.
Once I split it this way, the logs went quiet. The context window stopped filling with noise the model would only have rubber-stamped, the transient stuff a for loop handles got handled by a for loop, and the model spent its attention only on the errors where its reasoning actually helped. You’re not hiding failures from the model. You’re being deliberate about which ones are worth its time.
That’s the mental model, and it’s most of the battle. Every tool failure has a kind, and the kind decides where it goes: the harness retries what a retry can fix, the model sees only the errors its reasoning can move, and the failures nothing can fix end the run instead of spinning it.