Show your working: chain of thought and why it works
Why "let's think step by step" worked, why reasoning models work for the same reason, and what changes for anyone building on top.
Before reasoning models existed, there was a single-line prompt trick that did a lot of the heavy lifting in every serious system prompt I wrote. The line was:
Let’s think step by step.
You stuck it on the end of your prompt and the same model, on the same question, would start getting things right that it had been getting wrong for weeks. It wasn’t a clever line and it was almost embarrassingly simple. But for a long stretch, roughly 2022 through to when reasoning models like o1 were released - it was one of the most reliably effective things you could do to a prompt.
The technique is called chain of thought. And although the trick itself is mostly gone now - absorbed directly into the models - the mechanism it relied on is still doing all the work inside every reasoning model you use today.
The show-your-working rule
If you did maths at school you’ll remember the “Show your working” rule. Teachers didn’t just want the answer, they wanted the steps. There were two reasons for this. Firstly, they wanted to give you partial marks if the final number was wrong. The second was more interesting - they knew the steps weren’t separate from the thinking. The steps were the thinking. You don’t reliably arrive at the right answer to a multi-step problem by staring at it and producing a guess and relying on probability to get it right. You arrive at it by going through it.
Chain of thought is the same idea, applied to a language model. Instead of asking the model for an answer, you ask it to lay out the reasoning that leads to the answer, and then give the answer at the end. In its earliest form the technique was few-shot - you’d include a couple of worked examples in your prompt and the model would copy that pattern on new questions. Pretty quickly people noticed you didn’t even need the examples. “Let’s think step by step”, on its own, was enough to do most of the work.
There was a related trick that came out around the same time called self-consistency, where instead of generating one chain of thought you’d sample several, take the answer they mostly agreed on, and throw away the outliers. This work was inspired by a 2022 paper that defined that all correct reasoning paths tend to converge on the same answer, while incorrect paths diverge. The approach worked for the same underlying reason but used more tokens and compute. For most tasks plain chain of thought was the better trade.
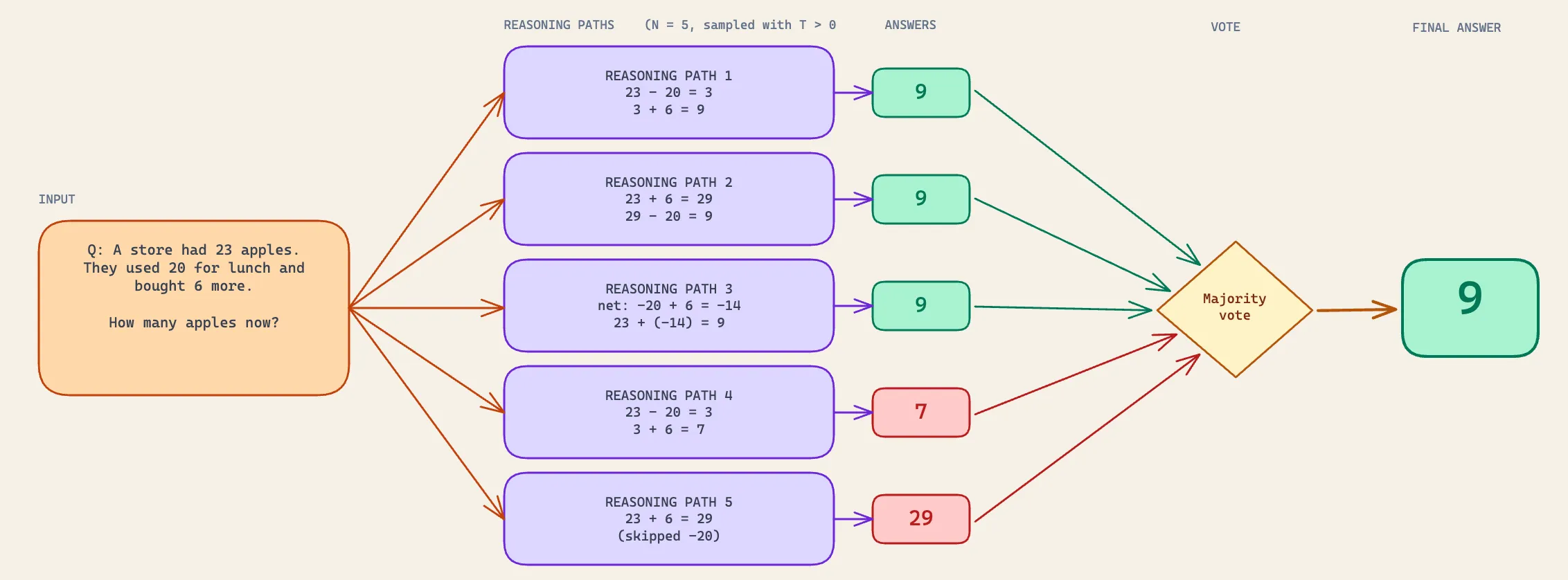
Why writing it down changes what the model can do
This is the bit that took me longer to understand. It’s also the bit that makes everything else about chain of thought, and everything about reasoning models, make sense.
A language model has no hidden state between tokens. Whatever it “knows” mid-answer has to be written into the output stream and read back in on the next step. There’s no scratch memory. No silent calculation. No quiet bit of working happening off-screen between when the model reads your question and when it produces the first word of its answer. There is only the sequence of tokens it has generated so far, which becomes the input on the way to producing the next one. The model is autoregressive, meaning it predicts what comes next based on everything that came before, including its own output.
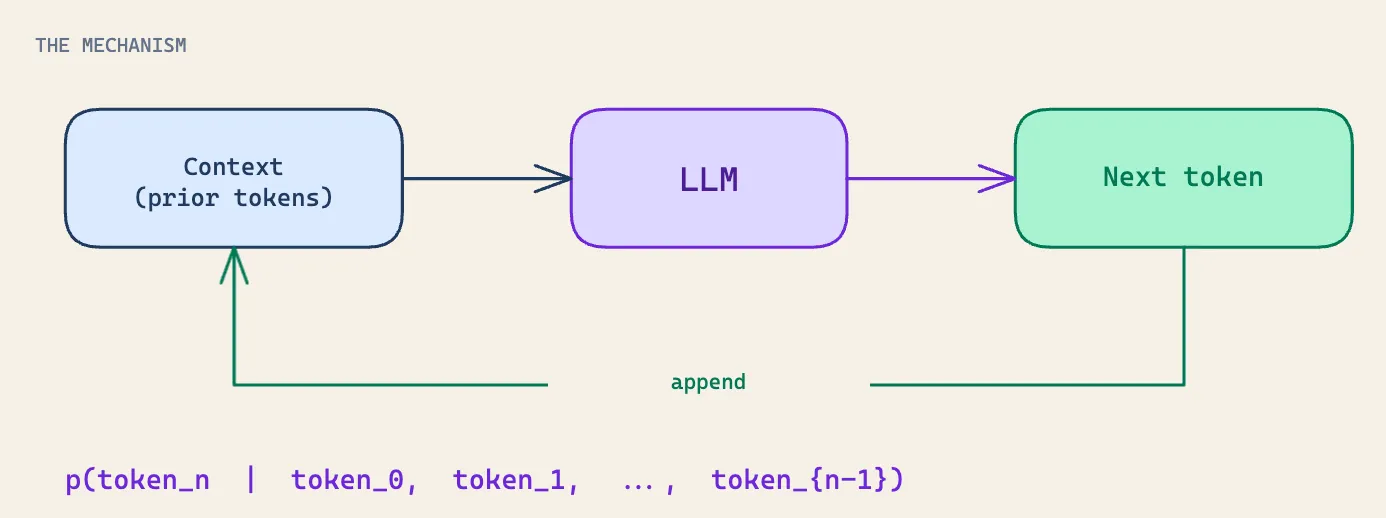
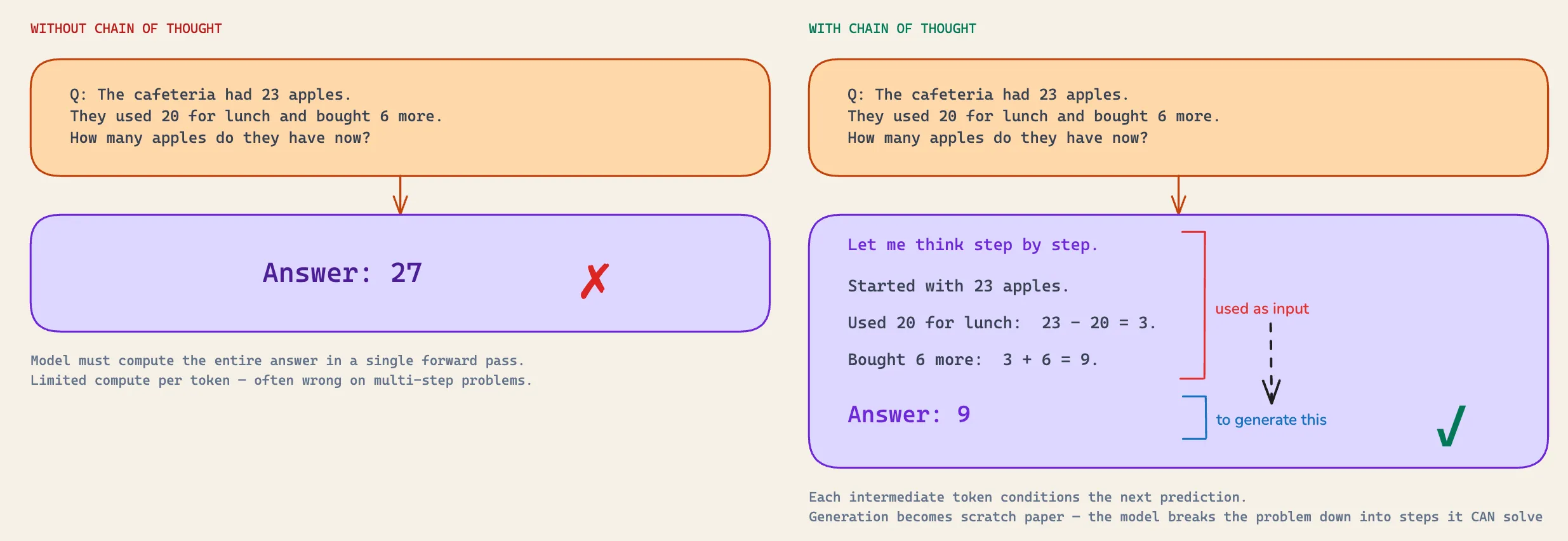
That sounds abstract until you sit with what it actually means. When you ask a model a hard question and demand an immediate answer, you are asking it to produce the right token with no room to work. There is nowhere for intermediate computation to live. One shot, from question to answer, and no scratchpad in between.
When you ask it to think step by step, you give it that scratchpad. Each reasoning token it generates goes into the context, and every subsequent token, including the final answer token - is conditioned on those intermediate tokens. The reasoning isn’t a polite explanation tacked onto an answer the model already had in mind. The reasoning is the base the answer is computed on.
This is why a sentence as bland as “let’s think step by step” worked at all. You weren’t making the model smarter. You were giving it somewhere to put its working.
From a trick to a feature
For a couple of years, chain of thought lived in the prompt. You asked for it, the model gave it, you parsed the answer out of the back of the response. The reasoning effort was on you - you had to remember to ask. And there were limits. The model would think out loud if you nudged it, but it wasn’t particularly good at thinking out loud. It would sometimes go down obviously wrong paths and not notice. It rarely backtracked. The chain was usually a single straight line - useful, but not how a human actually solves a hard problem.
Then the frontier AI labs did something obvious in hindsight. If thinking out loud reliably produces better answers, why are we relying on the user to ask for it? Why doesn’t the model do it by default? And the part that really changed things - what happens if we train the model to be good at thinking out loud, instead of just prompting it into the behaviour?
That’s where the reasoning models came from. Claude with extended thinking, OpenAI’s o-series, DeepSeek’s R1, all the others that followed. They share the same basic move. Chain of thought isn’t something you have to remember to add to your prompt any more. It’s been trained into the model - the model is rewarded during training for producing reasoning that leads to a correct answer, and shaped over many iterations to do this well. The result is a model that doesn’t just think out loud but thinks out loud productively. It backtracks, it checks itself, it spots when it’s confused itself and starts again.
The underlying mechanism is identical to the original prompting trick. The model is still using generated tokens as a scratchpad. What’s different is that it’s been shaped to use them well, and as the developer you now have a knob exposed to you called the thinking budget. Want a better answer on a hard question? Let the model think for longer. More tokens, more working, generally better answers. You can buy accuracy with tokens.
That last sentence is the actual conceptual shift, and it’s worth sitting with. Chain of thought in 2022 was a hack that coaxed more performance out of a fixed model. Chain of thought in 2026 is a lever on the model itself, and it’s reshaped how the whole field thinks about inference.
What I got wrong about it
A couple of things tripped me up and I see the same things catch out other people building with this stuff.
The first was assuming the chain of thought was a window into how the model was actually reasoning. When the model writes out its working, it really does feel like you’re watching it think. That’s not quite right. The stated reasoning isn’t always the path the model actually took to its answer. Some of what the model writes is, in part, a post-hoc rationalisation - a story that fits the answer rather than the calculation that produced it. I used to debug agent failures by reading the thinking blocks and trusting them at face value. Sometimes that’s fine. Sometimes the trace looks fine and the actual failure is somewhere the trace doesn’t surface at all. I learned to pair the trace with real eval signals. What the model says it did, and what the model actually did, are not always the same thing.
The second was assuming more thinking is always better. Thinking tokens aren’t free. They cost money, they add latency, and they fill up the context window. On long-running agent tasks I started seeing the accumulated reasoning across multiple turns drown out the original goal. By step eight or nine the model would produce thoughtful, well-reasoned, completely off-topic actions. There’s a sweet spot - enough scratchpad for the model to work, not so much that it loses the thread of what it’s meant to be doing. Finding that sweet spot is a real engineering decision. It’s not a “turn the slider up” exercise.
What this changes about how you build
If you’re building anything non-trivial on top of an LLM in 2026, chain of thought has stopped being a prompt tweak and become an architectural decision.
For single-call tasks, the question to ask isn’t “is the prompt good enough?” but “does the model have room to work?” A model with no scratchpad will fail on anything that needs real multi-step reasoning, no matter how clever your instructions are. Turn on extended thinking. Calibrate the budget to the difficulty of the task. Stop trying to compensate with prompt phrasing for a model you haven’t given any space to think.
For agents - and this is where the next article picks up on, every reasoning step inside an agent loop is, in effect, a chain of thought. The Thought step in a ReAct loop is exactly the same mechanism we’ve been talking about - the model using generated tokens as a workspace to decide what to do next. The quality of that workspace is what determines whether the agent picks the right tool. Once you see it that way, a lot of agent failure modes stop looking like prompt problems and start looking like a model not having been given enough room to think.